はげったーを支える技術(CDN編)
ご無沙汰しております。 前回の更新から2年が経過しておりますが、みなさまはいかがお過ごしでしたでしょうか。 僕はななさいになりました。
Mastodon(主にhandon.club)向けのTogetterライクなサービスとして、hagetter(はげったー)*1というサービスを開発・運用しており、気がむいた時にその中身の技術について紹介しています。
今回はCDN編となります。はげったーはCloudRunでホスティングしているためコールドスタートの立ち上がりに時間がかかり、レスポンスが遅いとのコメントをたくさん頂いていたので、今回の更新でCDNを使ったレスポンスの改善を行いました。
はげったーは皆様知っての通り1日十数アクセスの超人気サイトで、さらに不定期に記事が更新されるので、CDNキャッシュのメリットを活かしにくいという課題がありました。 CDNキャッシュのパージを用いて、キャッシュヒット率を上げつつコンテンツ更新が即時に反映される仕組みを作ったのでご紹介します。
前半ではCDNを用いたキャッシュの一般的な仕組み、後半でははげったーでの実装についてご説明します。
2022/7/20追記:プロキシサーバーの共有キャッシュが長時間残ってしまう問題をうまく回避する方法が見付からなかったので、若干不完全な内容となります。。(プロキシサーバーなしでは問題なく動作します)
過去の記事はこちら
目次
CDNの基本的な仕組み
CDNはContent Delivery Networkの略で、地理的に分散したサーバーにWebサイトのコンテンツをキャッシュすることで、Webアクセスを高速化します。また、高速化だけでなく、運営するWebサービスの負荷低減やDDoS対策などのセキュリティ上のメリットなどもあります。
CDNを利用する際には、運営するWebサイトのDNSレコードをCDNに向けるなどして、Webサイトのアクセスの際にCDNサーバーを経由するようにします。CDNを経由することでWebサイトのレスポンスが自動的にCDNのサービスにキャッシュされ、新たなリクエストが来た時にはCDNがWebサイトにリクエストすることなくキャッシュから返却します。
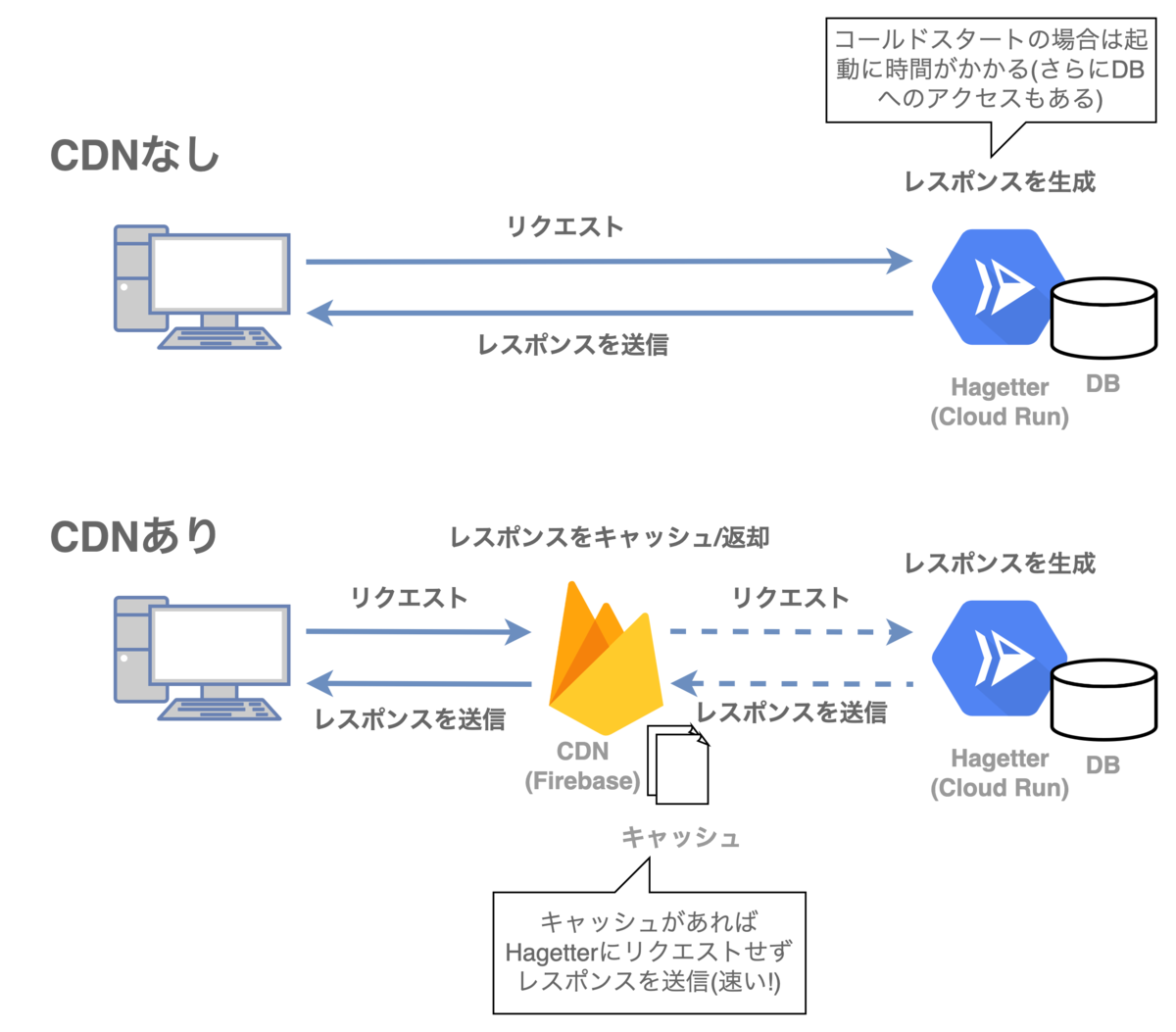
ただし、Webサイトのレスポンスは静的なものだけでなく動的に変化するものも混在しているため、ただ一律にキャッシュすれば良いというわけにはいきません。そこでWebサイトがレスポンスを返却する際にCache-ControlヘッダなどのHTTPヘッダを用いてキャッシュの挙動を変化させることが出来ます。
キャッシュまわりの設定はかなり複雑なので、今回は関係ありそうな部分のみかいつまんで説明します。
Cache-Controlヘッダ
キャッシュ制御に関するヘッダでリクエストやレスポンスに付与します。Cache-Controlはキャッシュの保存可否や保存期間などの挙動を複数のディレクティブを用いて指定します。
ここでは主にレスポンスに付与されたCache-Controlヘッダについて述べます。
詳細はMDMの仕様説明をご参照下さい。
キャッシュの種類
キャッシュの種類は大きく分けて「プライベートキャッシュ」と「共有キャッシュ」に分けられます。
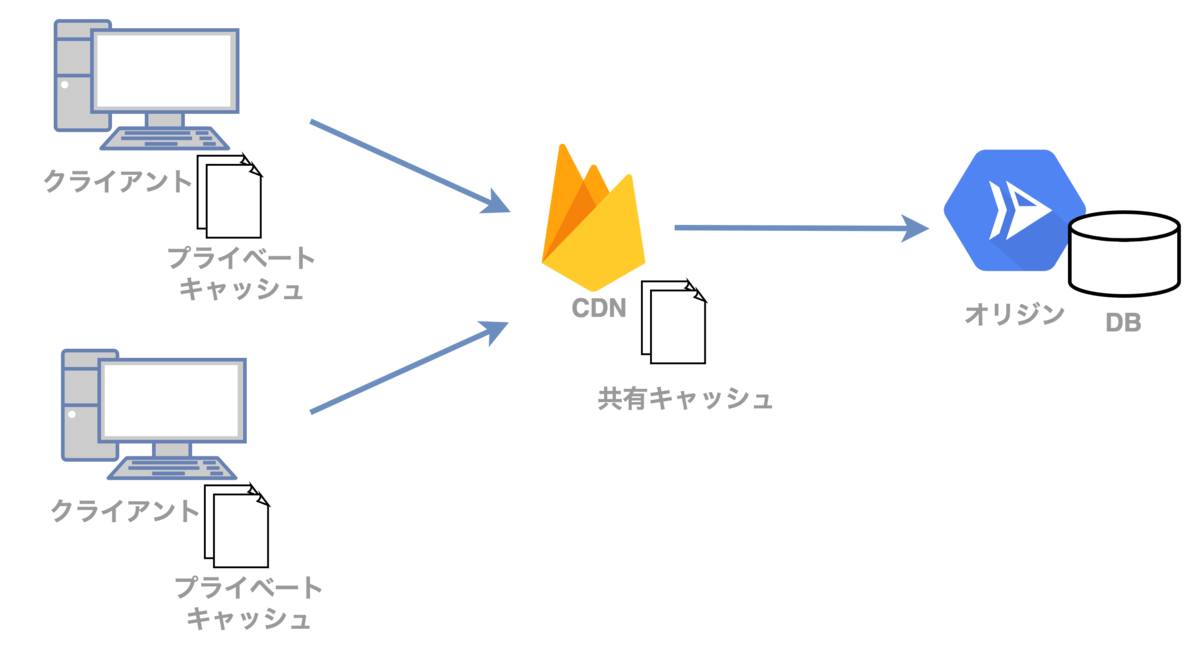
プライベートキャッシュ
ブラウザなどのクライアント環境内に存在するキャッシュです。ログイン後のページなどのパーソナライズドされたコンテンツもキャッシュすることが可能です。Cache-Controlにprivateを指定したレスポンスはプライベートキャッシュのみに保存可能で、CDNやプロキシサーバーには保存されません。
Cache-Control: private
Cache-Controlでpublic/privateを明示しなかった場合は、デフォルトではprivateキャッシュとなるようです。ただし、s-maxageなどの一部の共有キャッシュに関する設定値によってデフォルト値がpublicに変わることもあります。
共有キャッシュ
CDNやプロキシサーバーなどに保存されたキャッシュです。キャッシュは他のユーザーも利用することが可能です。そのためパーソナライズドされたコンテンツはキャッシュしてはいけません。共有キャッシュとしての保存可否は他のヘッダやCache-controlのパラメータによって変化しますが、publicを指定することでキャッシュ可能なことを明示出来ます(長くなるので詳しくは仕様書を参照下さい)。
Cache-Control: public
キャッシュの生存期間
キャッシュが「新鮮」である期間を「max-age」で指定可能です(プライベート・共有キャッシュ共通)。また、「s-maxage」を指定することで共有キャッシュの設定値のみを変化させることも可能です。「新鮮」であるとはキャッシュしたコンテンツをオリジンに問い合わせることなくそのまま利用可能であるということを意味します(≠キャッシュの保存期間)。max-ageで指定した期間を過ぎると、キャッシュを更新する必要があります。
ただし、max-ageの期間を過ぎたらコンテンツを必ず再ダウンロードするというわけではなく、リクエストの際にIf-Modified-Sinceのパラメータを指定して、コンテンツが更新されていた際のみダウンロードします。サーバーはクライアントのキャッシュがそのまま利用可能な場合は、コンテンツの本体を送信せずに304 Not Modifedの応答を返します。これによって巨大なデータなどのキャッシュの再ダウンロードを避けることが出来ます。
パラメータの例
Cache-Control: public, max-age=10
キャッシュはpublicかつ、プライベート・共有キャッシュともに10秒まで利用可能です。
Cache-Control: max-age=10, s-maxage=100
プライベートキャッシュは10秒、共有キャッシュは100秒まで利用可能です。
Cache-Control: max-age=0
これはキャッシュを保存しないという意味ではなく、キャッシュとして保存した上で毎回コンテンツが最新かどうかの問い合わせを行います。コンテンツが更新されていた場合のみコンテンツを再ダウンロードします。コンテンツが巨大かつある程度の頻度で更新される可能性がある場合に有用です。
ちなみにキャッシュを一切保存させたくない場合はno-storeを指定します。(no-cacheはキャッシュを保存しないという意味ではなく、max-age=0, must-revalidate相当らしいです)
キャッシュが更新出来ない場合の挙動
max-ageで設定した時間を超えて例外的に古いキャッシュが利用される場合があります。例えばオリジンサーバーが503 Service Unavailableなどのエラーを返却して最新のコンテンツを取得出来なかった場合です。
エラー時にキャッシュが利用されないようにしたい場合は下記のようにmust-revalidateを追加すると、上記のような場合にはエラーを返却します。
Cache-Control: max-age=100, must-revalidate
参考:
同じURLで返却するコンテンツを変化させたい時どうするか?
例えばPCとスマホで返却するHTMLを変えたい時など、クライアント環境毎に異なるレスポンスを返却している場合があるかと思います。 この場合CDNでキャッシュするとクライアント環境によらず同じレスポンスが返却されることになるので不都合が生じます。 CDN毎にも異なるのですが、Cache-Control以外にもいくつかキャッシュの挙動に影響を受けるヘッダがあります。
例えばVaryヘッダです。Varyで指定されたリクエストヘッダの値をキーとして異なるコンテンツをキャッシュすることが可能です。ただし、HTTPリクエストのヘッダはブラウザが付けるものですので、Varyでの制御はなかなか難しいです。Fastlyの挙動に関する説明ですが下記サイトが参考になります。
他にも、Firebase HostingではCookieの__sessionというキーの値によって返却するレスポンスを変えることが可能です。例えばPCやモバイル、タイムゾーンなどをCookieに保存しておけば環境毎に異なるレスポンスを返す事は可能です。Firebase Hostingが__session以外のCookieを削除してしまうのですが、安直にここにセッションIDなどを入れてしまうと、セッションID毎に異なるキャッシュが生成されてしまい、ちゃんとキャッシュがきかなくなるので要注意です。
CDNのキャッシュのみに影響を与えたい時はどうするか?
Cache-Controlのs-maxageはCDNだけでなく通信経路上に存在するProxyサーバーにも影響が及びます。 今回のキャッシュパージのようにCDNのみにキャッシュしたいユースケースも存在します。
CDNのみにキャッシュをさせたい時は、CDN-Cache-Controlというヘッダが提案されていますが、現在実装しているのはCloudflareのみのようです。 他にも例えばFastlyならSurrogate-Controlというヘッダも利用可能です。
例えばFastlyに下記のようなヘッダを送った場合は、CDN(Fastly)では100秒、Proxyサーバーでは50秒、ブラウザでは10秒キャッシュが有効となります。
Surrogate-Control: max-age=100 Cache-Control: max-age=10, s-maxage=50
リクエストにおけるCache-Controlについて
最初にご紹介したようにCache-Controlはレスポンスだけでなくリクエストヘッダにも付与することが可能です。 クライアント側がCDNのキャッシュを無視して最新のコンテンツを取得したい場合などに利用します。
例えば、ブラウザでは通常のリロードの際には max-age=0、スーパーリロードの際には no-cacheをリクエストに付与するそうです。
他にも、CDNに長期間保存されうるjavascriptファイルなどには myscript.js?id=12345678 のように乱数をつけたクエリを付与することによって、CDNから古いバージョンのjavascriptファイルのキャッシュなどが返却されないようにするCache Bustingと呼ばれる手法も存在します。(Next.jsのSPAまわりでこの仕組みが利用されているので後述します)
動的コンテンツにおけるキャッシュ戦略
ここまではキャッシュの仕組みについて紹介しました。静的コンテンツの場合はキャッシュ期間を長めにするだけですので割とシンプルですが、動的コンテンツの場合はそう簡単にはいきません。
動的コンテンツをキャッシュすると、当然ですがコンテンツが更新されてもキャッシュの期限が切れるまではキャッシュされたコンテンツが返却されることになります。例えばキャッシュ期間が1時間なら最大で1時間はコンテンツが配信されない可能性があります。(更新頻度が高くないかつリアルタイムの更新が重要でない個人ブログなどはこの方法でも良いかもしれません)
一方、10秒などの短かい時間を設定するとキャッシュ効率が下がります(アクセス数の多いサイトはこれでもかなり有効ですが、はげったーは1日十数アクセスなのでキャッシュが無いものとほぼ同じ状態になります)。また、運悪くキャッシュ更新のタイミングでアクセスしたユーザーはキャッシュを使えないのでレスポンスが遅くなります。
レスポンス高速化とキャッシュ効率を両立するための手法はいくつか存在しています。
コンテンツ差分の動的読み込み
動的コンテンツを静的にキャッシュして、更新部分だけをAPIなどから取得してコンテンツを更新する方法です。CDNの弱点を実装でカバー!
この場合はWebサービス側に差分を取得するロジックとコンテンツを更新するロジックを組込まないといけないので実装面では若干面倒です。また、単純に実装するとコンテンツが後からぬるっと書き変わったりするのでUIの実装も多少気をつかいます。
Pros: CDNに特殊な機能が不要
Cons: 実装がやや大変。UXに若干の影響あり。
stale-while-revalidate
stale-while-revalidateはCache-Controlの仕組みの一つで、コンテンツのキャッシュ期限が切れていた場合には、現在の古いキャッシュをいったん返却しておき、裏でキャッシュを更新するという方法です。この機能を用いることにより、キャッシュ更新のタイミングにおけるレスポンス遅延を回避することが出来ます。
例えば下記のように設定するとキャッシュが生成されてから100秒間はそのままキャッシュを利用し、100〜1100秒にアクセスがあると古いキャッシュを返却しつつ、裏でオリジンサーバーにリクエストを送りキャッシュの更新を図ります。
Cache-Control: max-age=100, stale-while-revalidate=1000
ただし、stale-while-revalidateは比較的新しい仕組みなのでCDNが対応している必要があります(有名どころは大体対応しているっぽい?)。また、max-ageのようにどの程度の期間キャッシュを保持するかの問題もあります。
stale-while-revalidateと同様の機能としてNext.jsではISR(Incremental Static Regeneration)と呼ばれる機能があります。実質的にVercel限定の機能とはなりますが、ISRを用いることでかなりシンプルに実装することが可能です。
Pros: キャッシュ更新時のレスポンスを高速化出来る。ほぼCDNの機能のみで完結する。
Cons: stale-while-revalidateに対応しているCDNを利用する必要がある。キャッシュ時間が短かすぎると活用出来ず、長すぎると古いコンテンツが再利用される。
CDNキャッシュパージ
コンテンツの更新時に対応するURLのCDNのキャッシュをクリアするという方法です。この方法であればキャッシュ期間をどれだけ長く設定していたとしても、コンテンツの更新のタイミングでキャッシュを削除することでリアルタイムでの反映が可能となります。
同様の機能をNext.js v12.1でOn-Demand ISRとして提供した時には少し話題になりました。
VercelでOn-Demand ISRを利用する場合であれば一瞬で実装可能ですが、この方法を一般的なCDNで利用するには結構骨が折れます。まずはURL毎のキャッシュパージに対応したCDNを利用する必要があることと、stale-while-revalidateのように共通規格が存在しない方法なのでCDN毎に実装方法が異なります。また、あるデータを更新した際に影響を受けるページを把握しておき、その全てのページのキャッシュをパージする必要があります(これはOn-Demand ISRでも同じ)。少しでもミスるとその長いキャッシュ期間の間、ずっとコンテンツが更新されないことになります。
キャッシュパージに対応したCDNは例えば下記のようなものがあります。
- CloudFlare
- Google Cloud CDN
- Fastly
- Firebase Hosting (※公式ドキュメントに記載なし)
料金や制約などは下記サイトが情報がまとまってて参考になります。
CDNのパージとかを調べてみたまとめ(Cloudflare/Cloud CDN/Fastly) - くらげになりたい。
Pros: キャッシュ期間をどれだけ長くしてもコンテンツ更新がキャッシュにリアルタイムに反映される
Cons: キャッシュパージを利用可能なCDNが限られる。CDNによってキャッシュパージの方法が異なる。データ更新時に影響を受けるページを把握しておく必要がある。実装がとにかく大変。
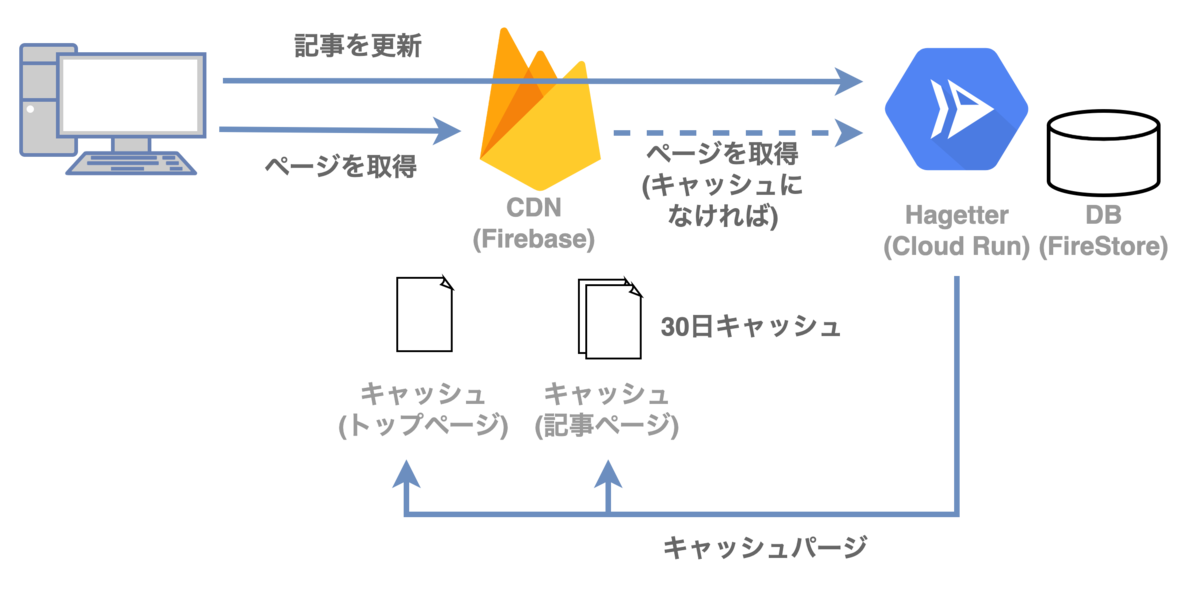
はげったーでのキャッシュパージによる高速化
ここまでで一般的なキャッシュまわりの技術について簡単に紹介しました。ここからはやっとはげったーにおける実装の話です。
はげったーはこれまでCloud Runを単体で利用していましたが、CDNによるキャッシュとキャッシュパージを利用するために以下のような構成にしました。 CDNとしてFirebase Hostingを使ったのは、同じGoogleのサービスであることとCDNやキャッシュパージの機能を無料で利用出来るという理由からです。
- CDN:Firebase Hosting
- サーバー:Cloud Run
- ソフトウェア:Next.js
各部分の実装について説明していきます。
はげったーのキャッシュ戦略
はげったーで高速化のためにキャッシュしたいページは下記2種類です。
- トップページ
- 各記事のページ
上記のページはSSRで静的コンテンツを出力し、Cache-Controlヘッダにmax-age=0, s-maxage=21600を指定しています。 これはクライアントはキャッシュが最新かを必ずCDNに問い合わせ、CDNは6時間(21600秒)のキャッシュを保有するという意味になります。
ユーザーがはげったーで記事を更新した際には、記事本体と記事一覧のあるトップページそれぞれのCDNキャッシュをパージしています。
これで、ほぼ常にCDNのキャッシュにヒットする上に、記事に更新があった際にも即座に反映されるという夢のような仕組みになります。
2022/7/20追記:元々s-maxageは30日に設定していましたが、後述するようにFirebase HostingではSurrogate-ControlがきかずProxyサーバーに長期間キャッシュが残る可能性があったため6時間に変更しました。(微妙・・)
Firebase HostingのCDNキャッシュパージ
Firebase HostingではCDNとしてFastlyを利用しているらしく、Fastlyと同様の方法でキャッシュをパージすることが可能です。FastlyではキャッシュしたURLにPURGEというメソッドでリクエストを送信するとそのURLのキャッシュを削除することが可能で、Firebase Hostingでも問題なく利用できました。検索していたらGoogleのエンジニアがMLに投稿しているのをたまたまみつけました。
これをもとに試しに実装してみたらサンプルがこちらです。 上がCDNにキャッシュされた時刻、下がJavascriptで同的に取得した時刻です。リロードすると下の時間だけ動くのが分かるかと思います。
レスポンスのCache-controlヘッダはmax-age=0, s-maxage=31536000ですので、CDNには最大で365日共有キャッシュが保存されます。
ボタンを押すとAPI経由でトップページのURLにPURGEメソッドでリクエストを送信され、キャッシュがクリアされます。
ソースコードは下記にあります。 github.com
Firebase HostingとCloud Runの連携
Firebase HostingからCloud Runにリクエストを振り分ける方法は下記が参考になるかと思います。今回はFirebase Hostingのホスティング機能は利用せずに全てCloud Runから配信しています。
Firebase Hosting + Cloud Runの構成の場合、Cookieは__sessionというキー以外はFirebase Hosting側で削除されてCloud Run側に到達しないので注意が必要です。また、__sessionはキャッシュのキーとして組込まれているため、適当に設定するとキャッシュがちゃんと動作しなくなる点も要注意です。ログイン情報をCookieで管理していて、サーバー側でも利用したい場合は少し扱いが難しいです。
また、CDNを経由しているためCloud RunからはHostヘッダなどから自身のWebサイトのURLを取得出来ないことに注意して下さい。ググった範囲では X-Forwarded-Host ヘッダが付与されるとも書いてある記事を見かけましたが、自分の環境では現時点では付与されていませんでした。ですのでキャッシュのパージなどで自身のURLが必要な時は環境変数などで与える必要があります。
Next.js+Firebase Hostingでの自作On-Demand ISRの実装
長い前置きでしたがここでやっと本題のキャッシュパージの実装になります。
Next.jsでのCache-Controlヘッダーの送信
Next.jsでレスポンスヘッダーを書き換えたい場合にはgetServerSidePropsの中で指定することが出来ます。
export const getServerSideProps: GetServerSideProps<PageProps> = async ( context ) => { context.res.setHeader( 'cache-control', 'public, max-age=0, s-maxage=2592000' )
Next.jsとFirebase Hostingでのキャッシュパージの実装
Next.jsではSSRで生成されるコンテンツは2種類あります。 1つはコンテンツのHTMLで、ブラウザなどからURL指定でのアクセス・Aリンクからのアクセス・リロードの際に読み込まれます。 もう一つがnext/linkによるページ遷移の時に利用されるURLで、この時はコンテンツのURLにアクセスするのでなく、コンテンツに対応したjsonファイルが読み込まれてページの中身が書き変わります。
例えばNext.jsでコンテンツが提供されている https://example.com/ にアクセスがあったとすると、
- 直接アクセスの場合はhttps://example.com/
- next/linkでの遷移の場合は、 https://example.com/_next/{ビルドID}/index.json
のコンテンツが読み込まれます。コンテンツ更新の際にはこの2つのキャッシュを削除する必要があります。
ビルドIDはnext buildを実行した際に設定されるランダムな数値です(恐らくCache Bustingのため?)。ビルドIDは実行時に直接取得する方法が恐らくなさそうなので、next.config.jsで下記のように設定することで NEXT_BUILD_ID という環境変数経由でビルドIDを取得することが可能になります。
module.exports = { webpack: (config, { webpack, buildId, isServer }) => { config.plugins.push( new webpack.DefinePlugin({ 'process.env.NEXT_BUILD_ID': JSON.stringify(buildId), }) ) return config }, }
そして記事更新の際のキャッシュパージの実装は下記のようになります。
ここでは
https://hagetter.hansode.club/
https://hagetter.hansode.club/hi/{hid} ※hidは記事ID
の2つのURLのキャッシュを削除するものとします。
const purgeCache = async ( req: NextApiRequest, hid: string, ) => { const baseUri = process.env.BASE_URI // フロンドエンドのホスト名を環境変数で指定 const buildId = process.env.NEXT_BUID_ID // next.config.jsで設定 await Promise.all([ fetch(baseUri, { method: 'PURGE' }) fetch(`${baseUri}/_next/data/${buildId}/index.json`, { method: 'PURGE' }) fetch(`${baseUri}/hi/${hid}`, { method: 'PURGE' }) fetch(`${baseUri}/_next/data/${buildId}/hi/${hid}.json`, { method: 'PURGE' }) ]) }
今のところはパージのみ実施していますが、fetchで再読み込みなどすれば新しいコンテンツでキャッシュをあらかじめ生成しておくことも可能かと思います。
Proxyサーバーでのキャッシュの回避(2022/7/20追記)
これでCDNについてはキャッシュを更新することが出来ましたが、途中経路に存在するプロキシサーバーなどに長期間キャッシュが残る懸念があるのではないかとのご指摘を頂きました。これについては下記2パターンを試してみたのですが、今のところうまくいかないため回避策がないようでした。
- Surrogate-Controlヘッダを指定する … Fastlyでは問題なく利用できるのですが、Firebase Hostingではうまく動作しないようでした。Twitter上でも同様の問題にぶちあたっている人がいました。
- Firebase HostingのheadersルールでCache-Controlを書き換える … 変更後のヘッダの内容に基いてキャッシュされるようでしたので、こちらも残念ながら利用出来ませんでした。
現在はいったんキャッシュ期間を6時間ほどに設定しています。 Proxyも含めた正式対応はFirebase Hosting+FastlyがSurrogate-ControlやCDN-Cache-Controlに正式に対応するのを待つしかないようです。。
ビルドIDが変化した時のキャッシュ削除
記事更新時はこれまで説明した内容で動作しますが、ソフトウェアのアップデートなどによってビルドし直した際にはビルドIDが変化するため問題があります。
SSRしたコンテンツの中にはビルドIDが含まれているので、ビルドIDが変化した際にはコンテンツのキャッシュを一度削除した方が良さそうです。(jsonが404になるとフォールバックでURLに直接アクセスが飛ぶようなのでエラーにはならないみたいですが)
Firebase hostingの場合は、firebase deploy --only hosting で全体のキャッシュも削除されるようなので、ソフトウェアのアップデート時にはこのコマンドも実行しておくと良いかと思います。CIで自動的に実行するようにしても良いかもしれません。
これでNext.js + Firebase HostingでOn-Demand ISRの実装が完了しました。
Firebase HostingではなくVercelの場合
ちなみにVercelの場合はとても簡単で、APIの中で下記のようにrevalidateを呼び出すだけです。面倒な部分が全部隠蔽されて楽ちんです。
res.revalidate('/') res.revalidate(`/hi/${hid}`)
まとめ
今回ははげったーにおけるCDNによるレスポンス高速化について紹介しました。
次のネタは考え中です。
🌼🌼🌼 おまけ 🌼🌼🌼


*1:handon.club版togetterなのでhagetter
はげったーを支える技術(インフラ編)
Mastodon(主にhandon.club)向けのTogetterライクなサービスとして、hagetter(はげったー)*1というサービスを開発・運用しています。個人開発ということもあり色々と新しい技術要素を取り入れながら試行錯誤しながら開発しているので、その中身について少しずつ紹介していこうと思います。
今回はインフラ編です。神の手によって創造されたソースコードがどのように実環境に反映され、1日数十もあるアクセスを捌いているのかについて紹介します。
過去の記事はこちら
はげったーのデリバリ・パイプラインについて
はげったーではGithubにソースコードをpushすると自動的にビルドされて、GCP(Google Cloud Platform)の本番環境に反映される仕組みになっています。 下はその流れを示したありきたりな図です。

以降は各パートに分けて説明します。
Cloud Build
GCPの提供するCIサービスです。ここでソースコードのビルドやDockerコンテナの作成を行い実環境にデプロイしています。
トリガはGCPのCloud Source RepositoriesだけでなくGithubやBitBucketにも対応しており、HagetterではGithubのmaster/developブランチへのpushをトリガにビルドを開始しています。
(ちなみに当時はまだGithub Actionsが無かったのでCloud Buildを利用していましたが、今ならGithub Actionsでほぼ似たようなことが出来ます)


Cloud Buildの特徴はDockerコンテナを使ったパイプライン処理です。ソースコードディレクトリを様々なDockerコンテナに順番マウントしながら処理を進めていきます。これによって、複雑なビルド環境を構築したり、ビルド前に必要となるツールを使うためだけにビルド環境を汚すといった心配事から解放されます。

よく使うコンテナについてはGCPから提供されています。 https://console.cloud.google.com/gcr/images/cloud-builders/GLOBAL
Hagetterでは以下のようなパイプライン定義となっています(パイプライン定義はソースリポジトリ内に含める必要があります)。 ちなみにブランチ毎に環境を作れるのでdevelopブランチにpushすると試験環境へ、masterブランチにpushすると本番環境に反映される仕組みになっています。この辺はサーバーレスホスティングサービスのメリットですね。
steps: # create .env file - name: 'gcr.io/cloud-builders/docker' entrypoint: bash args: ['-c', 'echo ${_B64_ENV} | base64 -d > .env'] # build the container image - name: 'gcr.io/cloud-builders/docker' args: ['build', '-t', 'asia.gcr.io/$PROJECT_ID/hagetter-$BRANCH_NAME:$SHORT_SHA', '.'] # push the container image to Container Registry - name: 'gcr.io/cloud-builders/docker' args: ['push', 'asia.gcr.io/$PROJECT_ID/hagetter-$BRANCH_NAME:$SHORT_SHA'] # Deploy container image to Cloud Run - name: 'gcr.io/cloud-builders/gcloud' args: ['beta', 'run', 'deploy', 'hagetter-$BRANCH_NAME', '--image', 'asia.gcr.io/$PROJECT_ID/hagetter-$BRANCH_NAME:$SHORT_SHA', '--region', 'asia-northeast1', '--platform', 'managed', '--allow-unauthenticated', '--quiet'] images: - asia.gcr.io/$PROJECT_ID/hagetter-$BRANCH_NAME:$SHORT_SHA
- (docker環境) Hagetterで必要となる環境変数等の準備
- (docker環境) Dockerコンテナのビルド(ビルドファイル)
- (docker環境) コンテナリポジトリにpush
- (gloud環境) Cloud Runにデプロイ
本当は1と2の間にテストフェーズを入れたいのですがまたいずれ・・
Cloud Run
Cloud RunはGoogleが2019年に始めた最強のコンテナホスティングサービスです。 オンドマンドかつオートスケールでコンテナを立ち上げてくれるので、低コストでスケールするサービスを作る事が出来ます。 HTTPSとgRPCに対応しているのでWebサイトやAPIサーバーの運用にも使えます。
レスポンスの統計の確認やコンテナへのトラフィックの段階的な振り分けなんかも出来るのでまあまあ便利です。コンソール上に出力されたログも確認出来るのでエラー時にも調査しやすいです。



Cloud Runの最大のメリットは好きなコンテナを使う事が出来ることとコストでしょう。
HagetterではNext.jsを利用していますが、Next.jsではフロントエンドとサーバーサイドの両方の処理をまとめて書けるのでNetlifyやAWS S3のような静的な環境の場合少し工夫が要ります。
Cloud RunならDockerコンテナでnext startするだけです。サーバーサイドレンダリング(SSR)についても特に苦労せず実現可能です。
Cloud Runで実行するためのDockerfileはこれだけです。
FROM node # Setting working directory. All the path will be relative to WORKDIR WORKDIR /usr/src/app # Installing dependencies COPY package.json ./ RUN npm install # Copying source files COPY . . # Building app RUN npm run build # Running the app CMD npx next start --port $PORT
もう一点のコストですが、アクセス数(応答時間)に応じた従量課金なので非常に低コストの運用が可能です。似たようなコンテナホスティングサービスだとAWS Fargateなんかもありますけど、こちらは0からスケールするようなサービスを作る事は出来ないのでCloud Run以外では同種のサービスは存在しないのではないでしょうか。(一部のランタイムであればHerokuやGAEでも似たような事は出来る)
Hagetterのようにアクセス数のあまり多くないサイトをサーバーで運営すると、サーバー費が割と勿体無かったり、かといって安いサーバーにするとパフォーマンスの問題があったりと悩ましいところですが、Cloud Runなら自動スケールするので低コスト・高性能の両面を実現可能です。まあ課金は青天井になりますが(制限はかけれる)。 今のところ無料枠内(50時間/月)に余裕で収まっています。
ちなみにみきbotも実はCloud Run上で動いていたりします。はんどんからの通知をトリガにOpenCVで画像処理を行ってMastodonAPIで処理結果を投稿しています。
Cloud Runの制約としては、コンテナはステートレスかつユーザーへのレスポンス後に処理を出来ないというものがあります。例えばユーザーにレスポンスを返した後に裏でジョブを回す、みたいな処理は出来ません。その場合はPubSub等にトピックを投げてPubSubから再度Cloud Runを呼び出す必要があります。
また、memcacheとかの機構も無いので、APIの結果をキャッシュするみたいな事が難しく性能面で若干の課題があったりします。
WebSocketのようなものも利用出来ません(ユーザー管理のGKE環境なら可能らしい)。
まあそれぞれワークアラウントもあるので個人で使う分には全く問題にならないレベルです。
Cloud Runあんまり話題にならないけど素晴しいサービスなので是非みんな使いましょう!
追記:
パフォーマンス面の改善なら以下が参考になります。
開発のヒント
まとめ
今回はHagetterのインフラ部分について紹介しました。
次回ぐらいからはやっと内部の実装について紹介していきたいと思います。
🌼🌼🌼 おまけ 🌼🌼🌼


*1:handon.club版togetterなのでhagetter
はげったーを支える技術(ユーザー認証とセキュリティ)
Mastodon(主にhandon.club)向けのTogetterライクなサービスとして、hagetter(はげったー)*1というサービスを開発・運用しています。個人開発ということもあり色々と新しい技術要素を取り入れながら試行錯誤しながら開発しているので、その中身について少しずつ紹介していこうと思います。
今回はユーザー認証やセキュリティについて紹介します。

hagetterのユーザー認証について
hagetterではユーザー認証はMastodonインスタンスのOAuth認証に依存しており、hagetterとユーザー間のセッション管理にはJSON Web Token(JWT)を利用しています。また、hagetterでは個人開発ということもあり、アプリケーションがセキュリティ品質を担保出来ていない可能性があるという前提の元、アクセストークンなどの機密性の高い情報は可能な限りサーバー内部に保持しないという設計を行っています。(サーバーがハックされて利用者全員分のアクセストークンが漏れたら大問題なので)。
対応するMastodonインスタンスは以前はhandon.clubのみでしたが、最近頑張って複数インスタンスに対応し、現在はmstdn.jpでも利用可能です。(めっちゃ頑張った!)
一意なユーザー名
ユーザー認証を複数の認証プロバイダに依存しているので、複数インスタンスで一意にユーザーを特定出来る必要があります。例えば「osa9」というアカウント名だけですと、handon.clubとmstdn.jpのいずれのユーザーであるかを一意に特定することが出来ません。悪意のあるユーザーが別のインスタンスでosa9というアカウントを取ったとしてもなりすまし出来ないようにする必要があります。
また、仮にosa9のアカウントが消えた後に誰かが同名のアカウントを取り直したとしても以前のユーザーの情報を盗み見ることが出来ないような仕組みが必要になります。
つまり「一意なユーザー名」は「空間的な一意性」と「時間的な一意性」を有している必要があります。
空間的な一意性
Mastodon APIでアカウント情報を取得するとユーザー識別情報として「ID」「username」「acct」の3つを含んでいます。
Mastodonのドキュメントによるとそれぞれ下記のような定義になっています。
- id: (Integer) The account id header.
- username: (String) The username of the account, not including domain.
- acct: (String) The Webfinger account URI. Equal to username for local users, or username@domain for remote users.
idはそのインスタンス内で外部のインスタンスを含む全てのユーザーに一意に割り振られたIDです。あるインスタンスの中では一意ですが、複数のインスタンスでは一意ではないです。基本的にはMastodon内部のDBの外部キーとして用いられるものでしょう。
usernameは「osa9」とかそういうやつです。osa9といっても例えばhandon.clubのosa9やmstdn.jpのosa9が居るように、インスタンス内部の扱いにおいても一意ではないです。
acctは、ローカルユーザーはusername、他インスタンスのユーザーはusername@domainという形を取ります。つまりタイムラインに表示されるユーザー名です。あるインスタンス内では一意ですが、複数のインスタンスの場合は一意にはなりません。handon.clubにとってのosa9はosa9@handon.clubであり、mstdn.jpにとってのosa9はosa9@mstdn.jpです。
つまりMastodonのAPIで取得可能な情報の中には残念ながら複数インスタンスで一意なユーザー名は含まれていない、ということになります。
既に答えは出ていますが、「username@domain」とすれば複数インスタンスでも一意となります。 (http://handon.clubとhttps://handon.clubとhttps://handon.club:8080とかはどうなるか知らん)
hagetterの内部ではMastodon APIでユーザー情報やステータスを取得する際に、acctを上記のusername@domainに書き換える処理を行っています。(最初そのままacctを使っちゃってマルチインスタンス化の時に苦労した)
ちなみに「id@domain」はどうなのかというと、重複はないですが同一ユーザーのidがインスタンスによって異なるため不便です。(osa9@handon.clubは、handon.clubにおいてはid=55、mstdn.jpにおいてはid=512494)
時間的な一意性
こちらはIDを変更可能だったり削除されたIDを再取得可能なTwitterでよく問題になるやつですね。仮にosa9が気分でosa34にIDを変えたとしても、後からosa9を取得した人に自分のデータを盗み見られないようにしなければなりません。なので例えばTwitterのサードパーティサービスはユーザー名ではなくユーザーIDでユーザーを識別する必要があります。
Mastodon上では基本的にIDは変更/削除不可能らしいのでこの辺の問題は何もせずにクリアです。やったね。
ユーザー認証とセッション管理
ユーザーがOAuth認証でhagetterに対して認可を行うと、hagetterはそのユーザー情報やタイムラインを取得するためのアクセストークンをMastodonインスタンスから取得します(OAuthの細かい話は割愛)。hagetter上でのログインセッション管理についてはJSON Web Token(JWT)を用いています。
あえて図に起こす必要もないですが、以下のような認証フローになります。

JSON Web Token(JWT)とは
RFC7519で定められているトークンの仕様です。特徴としては認証クレーム(ざっくり言えばユーザーIDや付随情報)に暗号化(JWE)やデジタル署名(JWS)を施すことでクレームの改竄や捏造を防止していることです。(この記事内ではJWT=JWSとして扱います)
デジタル署名によって、サーバーはユーザー識別に必要な情報をJWTのセッショントークンとしてユーザーに渡すことで、DB等にセッション情報を保持しなくてもユーザーから渡されたトークンから安全に認証情報を取得出来ます。ちなみにJWTの仕組みではPayload部分は暗号化されていないので、ユーザー側からどのような情報が格納されているかを見ることが出来ます。
例えばhagetterではセッショントークンは以下のような形式になっています。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjoib3NhOUBoYW5kb24uY2x1YiIsInRva2VuIjoiYWJjZGVkZjEyMzQ1Njc4OTAiLCJpYXQiOjE1OTAzMDEyNjIsImV4cCI6MTU5MDM4NzY2Mn0.nkxmAKVmRQ1OWrRCzbPH3ViIsjxFqilVHWYQqqehYVE
header(JSON)とpayload(JSON)とheader+payloadのデジタル署名の3つをそれぞれBase64urlエンコードし.(ドット)で繋げた形をしています。JWT.ioというサイトにトークンを入れてみると下記のようにデコードされることが分かります。

ユーザー側はサーバーから渡されたトークンのpayload部分をデコードする事で、自身のユーザー名やトークンの有効期限(exp)を知ることが出来ます。サーバーは内部にトークンを保持していなくてもユーザーから渡されたトークンの署名を検証する事で確かに自身が発行したトークンであることを確認出来ます。便利。
ただし、署名しているとはいえユーザーの入力を完全に信用することになるので、いくつか注意点があります。例えばサーバー側でセッション情報を保有していないので、万が一トークンが漏れた場合に失効処理が出来ません(失効情報をDB内に保管すれば出来るけど本末転倒感)。また、JWTには署名を付与しないnoneというタイプがあるのですが、これを無条件に受け入れてしまうと改竄されたトークンで認証機構を通過してしまう可能性があります(JWTはアルゴリズム種別すらユーザーに持たせている!)。
この辺は認証サービスであるAuth0が頑張ってライブラリを作っているので、そのライブラリを使えばほとんどの危険性は回避可能です(感謝)。
注意点については詳しくは以下のブログが参考になるかと思います。
hagetterでのJWTの活用
hagetterではユーザーの認証情報やアクセストークンを可能な限りサーバー内に保持しない運用を行っています。そのためWebサイトへの攻撃者だけでなく管理者もアクセストークンを用いてユーザーのタイムラインを不正に覗き見出来ない安全設計になっています。
ではどこにMastodonから取得したアクセストークンを保持しているのかというと、ここでJWTの仕組みを利用しています。ユーザー認証の際にアクセストークンを暗号化しJWTクレームの中に含め、ユーザーから認証が必要なURLへのアクセスがあった時のみJWTトークンの中からアクセストークンを復号してMastodonに投げています。大まかな流れは以下の通りです。

まあJWTトークンを保有しているのはユーザー自身なので、アクセストークンを生で持っても良いといえば良いのですが、アクセストークンは有効期限が長いので万が一アクセストークンが漏れた際にも悪用が出来ないよう考慮して暗号化しています。hagetterのセッション情報は現在は24時間で有効期限が切れるようになっています。なんとセッションの有効期限もJWT内部に含まれています(Payloadのexp)。
データセキュリティ
ちなみに、まとめ作成の部分でも暗号技術が活用されています。
まとめ作成の際にユーザーリクエストに応じてhagetterがMastodon APIからそのユーザーのタイムラインを取得してユーザーに返答します(ここでJWTとアクセストークンの暗号化が利用されています)。ちなみにサーバーは取得したタイムラインを保持していません。これは保持する処理を書くのがめんd…DBにタイムラインを保存するとまとめに使われなかったタイムライン情報を後から消す必要がありますし、悪意を持ったユーザーに何らかの形で盗み見るされる可能性もあるのでセキュリティリスクが高まるという配慮です。(togetterとかはどうやってるんだろう?)

ユーザーは取得したタイムラインをこねくり回してまとめを投稿するわけですが、タイムライン情報はユーザーに渡してサーバー内部で保持していないため、悪意のあるユーザーにタイムラインを勝手に書き換えられて投稿される可能性があります。hagetterではタイムラインの捏造防止のために、ユーザーにタイラインを渡す際に暗号化したToot(Status)を付加し、投稿時にはこの情報を用いて元のTootを復元しています。

これによってセキュリティと安全性と利便性を両立しています。
セキュリティ設計全般に言えることですが、ユーザーはあらゆる不正を働くものとしてデータ設計を行う必要があります。
まとめ
hagetterのセキュリティは暗号技術の進歩に支えられています。
(もしhagetterにセキュリティホールを見付けたらこっそり教えてください)
🌼🌼🌼 おまけ 🌼🌼🌼

*1:handon.club版togetterなのでhagetter
Amazon Lightsailが値下げしたので各VPSサービスとコスト比較してみる
Amazon Lightsailが大幅値下げされたので、他のVPSサービスとコスパ比較してみました。
Lightsail
https://aws.amazon.com/jp/lightsail/
Amazon Lightsail が 50% の値下げと 2 つの新インスタンスサイズを発表
比較対象は、さくらVPS、Conoha、Ditial Ocean。
さくらVPS
Conoha
Ditial Ocean
https://www.digitalocean.com/pricing/
Vultr
https://www.vultr.com/pricing/
サービスの特徴を比較
さくらVPS
- 国内超有名サービスで安定している
- 大容量HDDプランがある
- 初期費用がかかる/月額制
- 石狩/東京リージョン
Conoha
Digital Ocean
Vultr
Lightsail
- Amazonのサービスなので安心感がある
- 値下げでかなり安くなった
- OSインストール時にアプリのデプロイが出来る
- 東京リージョンもある
スペックの比較
| メモリ(GB) | vCPU | SSD(GB) | HDD(GB) | 初期費用(円) | 月額(円) | |
| さくらVPS | 0.5 | 1 | 20 | - | 1080 | 685 |
| 1 | 2 | 30 | 100 | 1620 | 972 | |
| 2 | 3 | 50 | 200 | 2160 | 1705 | |
| Conoha | 0.5 | 1 | 20 | - | 0 | 630 |
| 1 | 2 | 50 | - | 0 | 810 | |
| 2 | 3 | 50 | - | 0 | 1750 | |
| Digital Ocean | 1 | 1 | 25 | - | 0 | 555 |
| 1 | 3 | 60 | - | 0 | 1665 | |
| 2 | 1 | 50 | - | 0 | 1110 | |
| 2 | 2 | 60 | - | 0 | 1665 | |
| Vultr | 0.5 | 1 | 20 | - | 0 | 389 |
| 1 | 1 | 25 | - | 0 | 555 | |
| 2 | 1 | 40 | - | 0 | 1110 | |
| 4 | 2 | 60 | - | 0 | 2220 | |
| LightSail | 0.5 | 1 | 20 | - | 0 | 389 |
| 1 | 1 | 40 | - | 0 | 555 | |
| 2 | 1 | 60 | - | 0 | 1110 | |
| 4 | 2 | 80 | - | 0 | 2220 |
(1ドル111円で計算)
見事にばらばらでコスパ計算しづらいですねw
回帰問題にして数値化して比較しようかとも思いましたがそれは多分違うと思うので直感的に比較してみます。
とにかく安いのが良いって人は、
Vultrの0.5GB/1Core/20GB … 389円
LightSailの0.5GB/1Core/20GB … 389円
DigitalOceanの1GB/1Core/25GB … 550円
メモリ重視なら、
LightSailの2GB/1Core/60GB … 1110円
LightSailの4GB/2Core/80GB … 2220円
Vultrの4GB/2Core/60GB … 2220円
vCPU重視なら、
さくらVPSの2GB/3Core/50GB … 1705円
Conohaの2GB/3Core/50GB … 1750円
みたいな感じでしょうか。
国内サービスはメモリ/vCPUのバランスが優れていますね。まあコア数が多いといってもオーバーコミットされてるのでスペックに直結するわけではないのですが…。
あとはGCE(Google Compute Engine)のf1-micro(0.6GB/1CPU)が1インスタンス無料で使えるのでこれを使うという手もありですね。